Platform
本ソフトウェアは,並列分散計算環境における人工市場シミュレーションのための開発・実行の基盤すなわちプラットフォームを提供する. また,標準的な逐次計算環境における開発・実行も可能とする.
人工市場シミュレーションを行う前に,研究開発者は市場を構成する
- トレーダエージェントの取引戦略
- マーケット†および価格決定メカニズム
- エージェントとマーケットの連携
などを含む,人工市場モデルを設計し,プログラムを書く必要がある.
† 本ソフトウェアでは,現実における1つの銘柄を1つの「マーケット」として抽象化している. マーケットとはある特定の商品に関する取引システムに相当すると考えてほしい.
並列分散環境でシミュレーションを実行するには,上記に加えて,
- データ配置の問題:計算ノード†にデータをどのように配置するか?
- データ通信の問題:計算ノード間でデータの交換をどのように行うか?
- タスク管理の問題:計算負荷をいかにして分散させるか?
といった問題を克服するため,シミュレーション開発・実行の基盤となる部分が必要である. しかし,大規模並列シミュレーションの必要があったとしても,人工市場を使う研究者(金融・経済の分野だろう)にとっては,並列分散環境に合わせたプログラムを書くことは労力のかかる作業といえる. また,並列分散環境では,上記の問題のため,率直な並列プログラムでは期待通りの性能をえられないことが多い. この状況を克服するには,人工市場を使う研究者が計算機科学の専門家と連携し,実現可能な解を探索することが要求される. 本ソフトウェアは,この問題に対してひとつの解決策となるシミュレーション開発・実行の基盤を提供する.
Philosophy
本ソフトウェアは,人工市場シミュレーションを行う研究者(おもに経済系,工学系だろう)を主なユーザと想定しており,並列計算の技術に疎い研究者でも並列環境で実行可能なシミュレーションプログラムを開発・実行できる設計を目標とする. この目標のため,本ソフトウェアは「人工市場モデル」と「計算実行モデル」を分離している.
人工市場モデル: エージェントシミュレーションの用語でいう「モデル」をさす. 金融・経済の分野の研究者が作成するのはこの意味でのモデルである. この意味でのモデルは,エージェントの取引戦略,マーケットの注文処理,金融ショックや金融規制などを含む.
計算実行モデル: 他方,計算機科学の分野の研究者が開発するのは,「人工市場モデル」(あるいは「問題」)をいかに能率的に計算するか,その計算の実行方法に関する「モデル」である. この意味でのモデルは,先に述べた,データ配置の問題,データ通信の問題,タスク管理の問題を含む.
この分離の導入によって,金融・経済の分野の研究者は並列計算技術の知識を十分にもたずとも技術を利用できる. ただし,一般に逐次処理と厳密に同じ条件のままでの並列化は困難であり,高い並列計算能率を達成するには,人工市場モデル側にも何らかの制約(具体的には,情報伝搬の時間遅れ)を想定してもらう必要がでてくる. 本ソフトウェアは,自然なカタチで人工市場モデルと計算実行モデルの間の制約(決まりごと)を定義し,それによって,金融・経済の分野の研究者が逐次環境とできるだけ同じように,しかし大規模な並列環境で,シミュレーション研究を実施可能にする. また,その制約を活用し,計算機科学の分野の研究者がより効率的な実行モデルを開発可能にする.
Preview
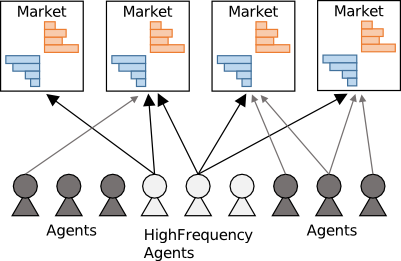
下記の図は人工市場シミュレーションの概略である. 図では,4つのマーケット(銘柄†)を取引する複数のエージェントが描かれている. マーケットは売りと買いに対応した板(オーダーブック)や価格の時系列といった情報をもつ. エージェントはこれらの情報をもとに,注文価格,注文量などを決め,注文を行う. エージェントからの注文はマーケットにより処理され,取引内容に応じて,次の時点の価格が決定される. 典型的な人工市場シミュレーション(逐次環境)では (i) エージェントの注文決定,(ii) マーケットの注文処理,が交互に繰り返される.
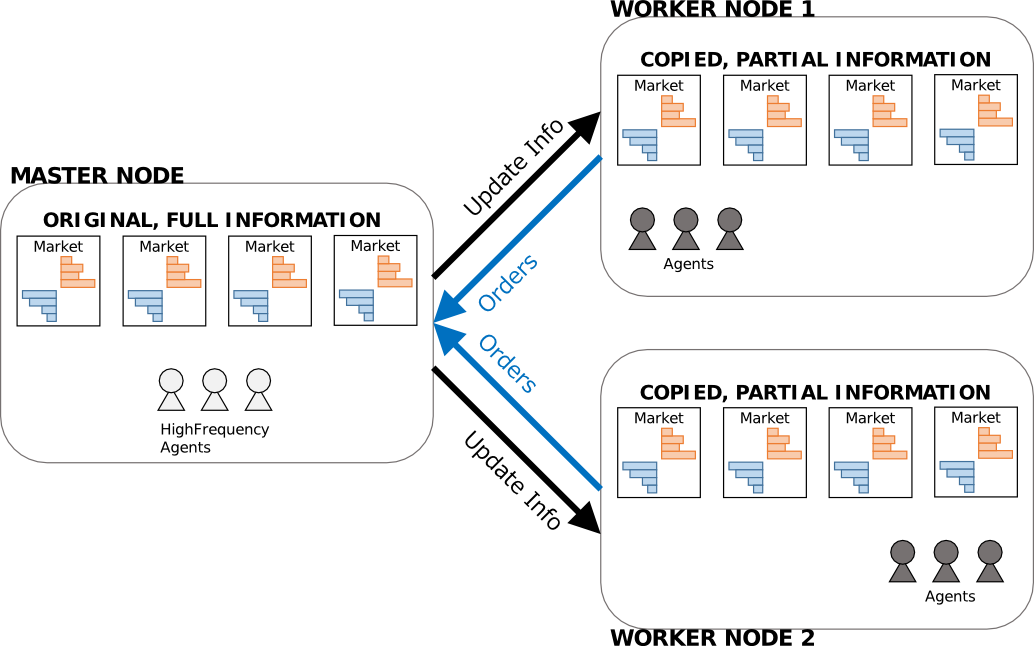
他方,次の図は並列分散環境における人工市場シミュレーションの概略である. ここでは,並列実行のイメージを掴んでもらうことが目的であるが,読み飛ばしても構わない. なお,図は並列環境のための計算実行モデルの一例である(他のモデルもありえる).
図では,3つの計算ノードがあり,1つのマスターノードと2つのワーカーノードからなる. この計算実行モデルでは,マスターノードは主に (ii) マーケットの注文処理を担う. 他方,ワーカーノードは (i) エージェントの注文決定を担い,これを複数の計算ノードで並列的に実行する. マーケットの最新の情報はマスターノードに置かれ,各ワーカーノードにはやや古い情報(遅延をともなうコピー)が置かれている. エージェントは各計算ノードに分散配置されている. このうち,常にティック時間レベルで最新の情報を要求する高頻度取引エージェントだけはマスターノードに,他方,秒足・分足などやや古い情報を要求する通常のエージェントはワーカーノードに分散配置されている. 通常のエージェントの注文は定期的にワーカーノードから集約され(図中,青矢印),マスターノードにおいて処理される. 最新の価格情報や資産情報は定期的に配信され(図中,黒矢印),ワーカーノードに置かれたマーケットの情報が最新のものに更新される. この計算実行モデルでは,上記の処理を並列分散的に繰り返し行う.
Key idea
読者の一部は,逐次実行と並列実行の区別が,本質的には計算実行モデルの違いであることに気づくだろう. 金融・経済の分野の研究者は人工市場モデルのプログラムを,それが逐次実行されるか,それとも並列実行されるか,とは無関係に作成できる. 換言すれば,人工市場モデルを開発する段階において,研究者はこれまで慣れ親しんだ逐次環境用にプログラムを作成すればよい. そして,実行する段階において,好みの計算実行モデル(逐次や並列など)を選択すればよい. ただし,上記の例にみられるように,並列実行の場合には,一部のエージェントが観察する市場の情報は最新ではない(遅延をともなう)ことを認めなければならない. これはそれほど強い要請ではないように思われる. 実際,現実においても,個人トレーダは高頻度取引の売買を追跡しているわけではない. 本ソフトウェアは情報の遅延をキーアイデアとして,高頻度取引やオプション取引など,時間スケールの異なる多様なエージェントが混在する状況を,並列分散環境で実行可能にすることを目指す.